
lostinbr
| Favorite team: | LSU |
| Location: | Baton Rouge, LA |
| Biography: | |
| Interests: | |
| Occupation: | |
| Number of Posts: | 12866 |
| Registered on: | 10/15/2017 |
| Online Status: | Not Online |
Recent Posts
Message
quote:
by Combaro01
That account is suspect as frick. Multiple bumps of months-old posts with subtle references to various businesses. Every post reads like AI.

 0
0
quote:
The organization says nearly 315,000 children as young as 10 were married in the U.S. between 2000 and 2021, mostly girls married to adult men.
What kind of clickbait bullshite is this?
The map shows that only 4 states allow marriage under the age of 15. And 2 of those 4 states have the “rate of child marriage” listed as “N/A.”
I found the actual data referenced in the article:
quote:
Nearly 315,000 minors were legally entered into marriage in the United States between 2000 and 2021. Eighty-six percent (86%) were girls, and most were wed to adult men an average of 4.02 years their senior.
Ninety-six percent (96%) of minors wed were aged 16 or 17, but some were as young as 10.
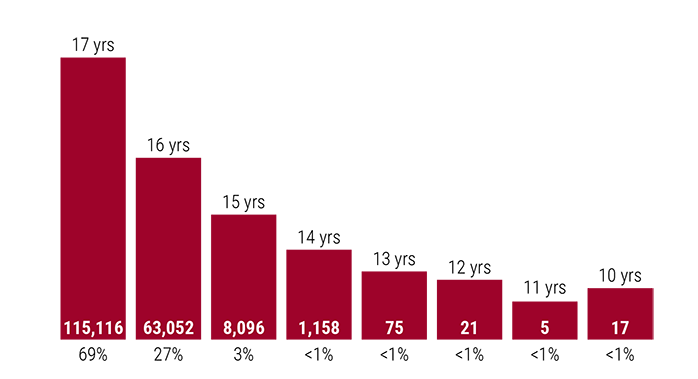
And then their graph has some weird scaling that makes 5 look like half of 1,158. :dunno:
That same organization says child marriages have decreased from 32,652 in 2000 to 1,717 in 2021. Even if we assume that the age distribution in 2021 was the same as the entire 22-year period (unlikely, it probably skews older due to changing laws), that would mean:
- About 12 people age 14 or younger get married each year in the US as of 2021
- About 1 person age 13 or younger gets married each year in the US as of 2021
It’s still fricking weird, but I don’t know that 17 year olds getting married is some huge societal issue - especially in states where 17 is the legal age of consent.
re: Flock camera map
Posted by lostinbr on 6/9/26 at 12:44 pm to fightin tigers
quote:
The 100% have the capability to feed into facial recognition but so far have led with "we only track cars" to get the entire system rolled out with support of naive citizens such as in this thread.
Yeah, I read an article about Flock selling their AI tools to a prison somewhere. Would have to dig it up, but if they can’t track people via facial recognition (among other methods) then I don’t see much point in using their service in a prison, where nobody is driving around.
I think the bigger concern about Flock is who they decide to sell access to, though. Right now they say it’s only government agencies/municipalities, businesses (e.g. for security purposes), and HOA’s. But tomorrow it could be insurance companies, advertisers, private investigators, employers, who knows?
They’re a private company building out infrastructure to track millions of Americans and analyze their movements. As far as I’m aware, there’s little/no legislation preventing them from selling access to whomever they please.
And it seems the government - or at least a good chunk of it - has little incentive to intervene because our law enforcement agencies have shifted toward using private companies as a workaround to bypass due process. Why get a warrant or subpoena for someone’s location data or browsing history when you just.. buy the information from Flock/data brokers without involving the courts at all?
It bothers me a bit that our society has just given up on the right to privacy. I feel like if you could go back in time to the early days of the internet and show people how all of this data is being used today, they’d see red flags everywhere. But now it’s been normalized to the point that the majority of the population simply doesn’t seem to give a shite.
quote:
11 for me one way to work. I don’t like this one bit. I knew this was trouble when I learned these cameras were donated to my local government for no charge.
I wonder who paid for this??? My guess is my federal tax dollars paid for this “security”.
As I understand it, Flock will often “donate” the hardware because of the subscription revenue they’ll generate over the long term. On top of that, Flock has maintenance contracts for the hardware.
Basically their business model isn’t selling cameras; it’s selling subscriptions to access their cloud storage, AI tools, etc.
quote:
Why the hell are we giving aliens a roadmap of how to come destroy us?
Be quiet in the dark forest night, lest the monsters hear you.
The closest star to our solar system today is about 4.2 light years away. Voyager 1, the faster-moving of the two probes, will take over 70,000 years to travel that far.
On top of that, the RTG’s providing power to the probes will be long dead by then. They won’t be broadcasting anything. They’ll just be tiny pieces of space junk hurtling through interstellar space, occasionally passing several light years from a star.
By the time either of the voyager records pass close enough to a hypothetical alien civilization to actually be discovered, we’ll either be interplanetary (maybe interstellar) or we’ll be extinct.
The Voyager records aren’t meant as a means to establish communications. It’s more like burying a time capsule in hopes that someone might find it long after you’re gone.
re: The “time price” of square foot of housing is 24% lower than the 1950s
Posted by lostinbr on 6/1/26 at 9:42 pm to HailHailtoMichigan!
quote:
This is the “dream house” that a 1965 auto worker in Michigan was living in

Zillow’s estimated market value for the house in that photo is $548,000. :lol:
quote:
This house being built today would not sell above construction costs:
According to Zillow, that exact house sold in 2023 for $1.3 million.
Here’s a Street View link if you doubt it’s the same house.
ETA: I see you’ve already been called out on this. But damn, I’m impressed at how well you managed to undermine your own point with those examples. :lol:
quote:
I know the EPA had mandated biofuels for years, and all the refiners already spent a bunch of capital building biodiesel units the last decade. I'm sure that's who is lobbying to increase the production if they are only running at 50% capacity.
I agree. Take a company like Valero, who has invested a ton of capital into renewable diesel over the past decade or so. They want a return on that investment.
Valero, P66, Marathon, Chevron, and PBF all have significant US investments in renewable diesel. Those are 5 of the 6 largest refiners in the country.
re: New Biodiesel Mandate Expected to be a Boon for U.S. Soy Farmers
Posted by lostinbr on 6/1/26 at 10:00 am to fightin tigers
quote:
The feed for renewable is more than they can sell the product for at this point.
Yeah, my understanding is that we basically overbuilt renewable diesel units and now there’s a shortage of raw tallow.
Which.. makes sense that it would be a boon to soybean farmers, if the “solution” is to ramp up vegetable oil production to fill that gap.
Seems like it kind of defeats the purpose though. These renewable diesel plants were originally making diesel from waste products. If they’re ramping up vegetable oil production to compensate, that means you have to grow the soybeans (using a lot of fertilizers, pesticides, water, etc.), refine them to vegetable oil (using hexane), hydrotreat the vegetable oil (using hydrogen produced from natural gas), and then process into finished fuel that is still chemically identical to petroleum diesel.
At some point you have to ask yourself “what is the point of this?”
re: Best way to build out/purchase a desktop
Posted by lostinbr on 5/31/26 at 9:19 pm to DarthRebel
quote:
Mem - 64GB DDR5
Storage - 2 TB M.2 SSD Boot
Prepare thine anus.
quote:
business use
quote:
CPU - Intel Ultra 9
RTX 5060 Ti
What kind of business use do you have that requires a Core Ultra 9 and discreet graphics?
You’re looking at a $3k+ build if you do it yourself (not including any peripherals). Prebuilt will be more. I’m not up to speed on where to buy prebuilt nowadays but I’d bet it’s north of $4k with those specs.
If you’re using the PC for really CPU-heavy software then OK. Or maybe you’re getting reimbursed or something etching in which case - hell yeah, man. Build away. But I’d wager you can easily save $1,000+ unless you have some really specific use case that requires those specs.
re: For All Mankind S5 (AppleTV) Spoilers
Posted by lostinbr on 5/30/26 at 6:45 pm to SouthEasternKaiju
quote:
I think the problem I have with these alternate history type shows is that they often ignore the sequence of events which lead up to the way things play out, and just take everything at face value. "Oh, we didn't do this first? OK, then we'd automatically pick up the role of what the others did and just carry on from there." That's not how history works, and I get it, the show needs drama and all, but I find the overall treatment to be clunky and simplistic.
I don’t really think For All Mankind does this at all, though.
re: Joe Rogan & a NASA astrophysicist talk about measuring time
Posted by lostinbr on 5/29/26 at 2:37 pm to CleverUserName
quote:
A clock measures the earth's rotation. As we stand here on it. Is that clock any good as you leave earth? Nope. It's a useless trinket then.
The original units may have been defined based on the rotation of the Earth, but the standard is no longer tied to that rotation. Nowadays the second is defined based on fundamental properties of matter - specifically the resonant frequency of Cesium-133. Which means that the origin of the unit might be meaningless on another planet, but the unit itself is just as applicable wherever you go.
But to your point, it’s really no different than any other measurement. The kilogram was originally defined based on the mass of 1 liter of water, but it’s just as meaningful when you’re measuring a container full of nitrogen.
quote:
Here's my thoughts. We can't actually measure time to begin with. Clocks are just ticking along to a frequency and not actually attached to time.
Nah. You could apply that same logic to any measurement. All measurement is the application of some arbitrary standard.
How do we measure distance, for example? If you want to know how many feet it is from point A to point B, you first define a “foot” and then you count the number of 1-foot increments between the two points in a spatial dimension. Time is no different. You define the “second” then count the number of increments between two points in the time dimension.
quote:
When an object moves through space at close to the speed of light, and it appears to lose time, but I think it's a problem with the time measuring device actually being physically slowed down. And not actual time being slowed down. The speed provides a resistance to things moving, such as the clock hands (or atoms) , and not an actual slowing of time.
It’s not that the fast-moving clock “loses time.” An observer traveling at high speed alongside the clock would see it tick at normal speed, but an observer in the rest frame would see it tick slowly. That’s the entire point of relativity - there is no universal time. The amount of time that passes in two different reference frames is relative.
re: Blue Origin rocket exploded on launch pad in Cape Canaveral, Florida
Posted by lostinbr on 5/29/26 at 12:09 am to TheRealTigerHorn
quote:
Werner and the boys blew up a few themselves.
I’d say they blew up more than a few.

re: Blue Origin rocket exploded on launch pad in Cape Canaveral, Florida
Posted by lostinbr on 5/29/26 at 12:05 am to NorthEndZone
quote:
That ought to be a significant insurance claim.
I’ve always wondered how that works. I mean I get that in this case it’s weird because Bezos, but for a normal commercial launch who is responsible for the cargo (and therefore responsible for the insurance)?
Guess I’m wondering what the Incoterms are for rocket payloads. :lol:
Long post, sorry.. but a thought experiment I’ve kicked around over the years:
I think a lot of people find the concept of spacetime unsatisfying because it seems inconsistent - why can we travel both directions in the space dimension, but only one direction in the time dimension?
So imagine I walk down a hallway from my bedroom to my living room. When I get to the end of the hallway, I can turn around and walk back to my bedroom. But when I get to the end of the hallway, I can’t rewind time back to when I left the bedroom.
But.. what if I could rewind time? What would happen? Well, since all of the chemical and electrical processes that formed my memory of walking down the hallway would reverse, I’d have no memory of it. So maybe time isn’t one-directional at all; maybe it’s just that our experience of time is one-directional because of how entropy shapes that experience.
Another way to think about it is: if being able to accept time as bidirectional requires us to somehow retain our memories, what’s the actual analog for that in the space dimension? So I walk down the hallway to the living room then somehow manage to isolate my brain/memories while time reverses and I end up back in the bedroom. What’s the spatial analog for that?
Well.. it would be like walking down the hallway to the living room, somehow isolating the hallway behind you, then walking back to the bedroom while your bedroom is still behind you. Just as the time example requires the bedroom to be both in your future and past when time reverses, the space example requires your bedroom to be both in front of you and behind you when you turn around. From that perspective, neither is possible - meaning both space and time are one-directional.
To me it seems that either A) both space and time are bidirectional and we just can’t wrap our heads around it because of memory/entropy, or B) neither space nor time are bidirectional and we’re just using flawed logic to convince ourselves that we can travel both directions through space. The distinction between the two options mostly comes down to how we choose to define bidirectionality.
Anyhow, that’s my TED Talk for tonight. :cheers:
I think a lot of people find the concept of spacetime unsatisfying because it seems inconsistent - why can we travel both directions in the space dimension, but only one direction in the time dimension?
So imagine I walk down a hallway from my bedroom to my living room. When I get to the end of the hallway, I can turn around and walk back to my bedroom. But when I get to the end of the hallway, I can’t rewind time back to when I left the bedroom.
But.. what if I could rewind time? What would happen? Well, since all of the chemical and electrical processes that formed my memory of walking down the hallway would reverse, I’d have no memory of it. So maybe time isn’t one-directional at all; maybe it’s just that our experience of time is one-directional because of how entropy shapes that experience.
Another way to think about it is: if being able to accept time as bidirectional requires us to somehow retain our memories, what’s the actual analog for that in the space dimension? So I walk down the hallway to the living room then somehow manage to isolate my brain/memories while time reverses and I end up back in the bedroom. What’s the spatial analog for that?
Well.. it would be like walking down the hallway to the living room, somehow isolating the hallway behind you, then walking back to the bedroom while your bedroom is still behind you. Just as the time example requires the bedroom to be both in your future and past when time reverses, the space example requires your bedroom to be both in front of you and behind you when you turn around. From that perspective, neither is possible - meaning both space and time are one-directional.
To me it seems that either A) both space and time are bidirectional and we just can’t wrap our heads around it because of memory/entropy, or B) neither space nor time are bidirectional and we’re just using flawed logic to convince ourselves that we can travel both directions through space. The distinction between the two options mostly comes down to how we choose to define bidirectionality.
Anyhow, that’s my TED Talk for tonight. :cheers:
quote:
Time is time. We just call it that bc some human naked it that centuries ago.
Same thing with distance. Light. Whatever.
I’m kind of with you on this. I think the distance analogy is spot on.
Like.. “distance” is a measurement of how far apart two points are in the spatial dimensions of spacetime, “time” is a measure of how far two events are apart in the time dimension of spacetime. They’re all linked together though, and both (distance and time) are warped by gravity and relative velocity.
I do think we struggle with understanding the significance of time on a cosmic scale, especially with the way we only experience time in one direction. But I think that’s more an entropy issue than a time issue - meaning entropy is the reason we can only experience time in one direction.
quote:
The way it ended the next episode has to be a continuation of this one. Glad to hear we are getting two episodes next week.
I suspect one of those episodes will be a retelling of this episode from Patricia’s/Wyck’s POV to fill in the gaps.
The flashback to his wife’s hospitalization was interesting. She was on the ferry when she lost her sight so.. she left the island and then died (presumably)? I wonder if she was intentionally trying to give birth on the mainland. And now their kid can’t leave the island because they really did turn the ferry around? Assuming the curse is real, anyhow.
ETA: Also, were we supposed to know who that was in the opening scene crawling through the snow? They were obviously eating the same mushrooms but I wasn’t clear on whether that was some mysterious flashback or someone I was supposed to recognize.
re: The lying and catastrophizing regarding AI Data Centers is reaching critical mass
Posted by lostinbr on 5/19/26 at 10:15 am to wallowinit
quote:
Your analysis is fatally flawed. You assume that there is absolutely no benefit to anyone anywhere anyhow from an AI data center and that technology stops dead in its tracks when that AI data center is built.
Wait.. let me make sure I’m understanding you correctly:
My point was that there are legitimate concerns about how data centers will affect the cost of electricity for the rate-paying public.
You’re saying that my analysis is “fatally flawed” because I’m not also considering the benefits of the data centers?
This line of reasoning implies 1) that you don’t dispute the concerns about cost of electricity and 2) that you believe the benefits of AI data centers outweigh that cost (in the literal sense of the word - dollars out of the public’s pockets).
To which I would say, emphatically: frick that.
These aren’t municipal projects owned by taxpayers. They aren’t even public-private partnerships. They’re assets wholly owned by for-profit companies.
But let’s assume for a moment that the folks running the AI labs are correct about the impact of AI. People like Dario Amodei, Demis Hassabis, and Sam Altman keep talking about how AGI is going to completely change our economy. They voice concern about the disruption to the job market. These are the same folks advocating for UBI as a stopgap. If we are truly facing an unprecedented concentration of wealth and power, why the hell would the public need to subsidize it? They should be subsidizing the public if that’s the case.
quote:
I think of this as more of an indictment on the energy policies over the past 20+ years, solar and wind turbines are "great" on paper but at what cost in terms of scaling up power on demand?
I don’t think the actual problem has much (if anything) to do with renewables.
The Meta data center in north Louisiana is planned for 5 GW. Average power consumption for the entire state of Louisiana was ~10.9 GW in 2024. Peak usage was obviously considerably higher, but this all illustrates the point: a single customer using 5 GW fundamentally changes the power market in the state.
The details of the contract between Entergy and Meta are secret. But Entergy, as a regulated utility, is guaranteed to recoup any costs (plus associated profits) that aren’t covered by the secret contract.. from the rest of the rate-paying public.
It’s a perfect example of “privatize the gains, socialize the losses” and it goes against the entire point of regulated utilities: transparency.
Today, average usage in LA is split roughly as follows:
- 32% residential
- 25% commercial
- 43% industrial
If the Meta data center reaches 5 GW, it will be:
- 22% residential
- 17% commercial
- 29% industrial
- 31% Meta
… that single customer with the secret contract becomes a larger consumer of power than any other entire sector in the state. If Meta “underpays” by 10%, everyone else’s price has to increase by ~4.5% to compensate.
Yes, that’s based on maximum planned capacity for the data center. And yes, the Meta data center in LA is huge by today’s standards. But that’s one data center, and it doesn’t look like they’re getting any smaller. Is this the precedent we want to set?
I think there are very good reasons to be concerned about locking ourselves into long term costs with zero transparency. We should be scrutinizing the contract details, not taking Entergy’s word for it. The importance of this deal to Entergy cannot be overstated. It’s a windfall for them. Of course they’re going to paint it in a positive light.
/rant
quote:
For Louisiana, people always say age of consent is 17, but they don't realize that if the other person is more than 2 yrs older than the 17yr old, then it's still illegal. It's just a misdemeanor. Whether or not it should be a crime is another question.
No, 17 is the actual age of consent in LA. The rule about 2 years applies if the person is younger than 17.
So in Louisiana:
- 17 and 24: legal
- 16 and 17: legal (<2yrs difference)
- 16 and 19: misdemeanor (2-4yrs difference)
- 16 and 24: felony (>4yrs difference)

Popular











